How I Made an AI Generate Synth1 Presets
This blog post is a technical explanation of my website that generates Synth1 presets - www.thispatchdoesnotexist.com
The code for the model is available here.
This article was written during the summer of 2020, so it may sound like some things are in the past. I’m now in North Carolina doing CSEd PhD things!
TL;DR Takeaways
- Refactor your data processing pipeline early and often
- Don’t be afraid to use models you don’t fully understand if it works (and it’s for something goofy)
Intro
In May I graduated from the University of Delaware. This August I’m moving down to North Carolina to begin my PhD in Data-Driven Computer Science Education. I decided to take some time off and enjoy these last few months of respite (as well as one can with COVID and all that) before I get on that #phdgrind.
I quickly learned that I really only need a few weeks of leisure to recharge and around early June I started to feel the itch to work on something computer related again.
It was around then when I found Nintorac Audio’s This DX7 Cartridge Does Not Exist. As an avid music nerd and someone who most definitely knows what a neural network is, I found my new obsession for the month of June.
Synth1: Every Bedroom Producer’s First VST
When I first got into music production in high-school, one of the most recommended synth-plugins to beginner’s was Dachi Lab’s Synth1. It’s simple yet versatile, has been around forever, and there’s tons of preset banks floating around on the internet so you can start making cool sounds immediately. The best thing though? It’s completely free!
Fig 1. The Synth1 Interface
There’s a giant compilation of 25,000 presets that floats around the internet, this huge amount of training data combined with how widespread Synth1 is, making an AI to generate Synth1 presets seemed like a no-brainer.
Data Wrangling Part 1
Exploring the Dataset
The first thing I needed to do was to see how hard it would be to transform Synth1 presets into a nice and easy format to feed into whatever model I design.
After cracking open one of the *.sy1 files, I was greeted with something like this:
Astro Belt-lk
color=green
ver=112
0,1
45,14
76,8
1,3
2,64
3,81
4,1
5,64
6,1
7,0
... etc.
The first line is the name of the preset. color is what color the preset is in Synth1’s preset browser. ver is a bit tricky, it’s what version of Synth1 the preset was made in (we’ll talk more about this later).
The remaining lines are key-value pairs for the different parameters of the patch. After some searching, I discovered this manual which details what parameter number controls. For example, the key 3 corresponds to osc2 tune. The set of values for each parameter is detailed further in the document, so osc2 tune takes integers from 0-127, making 64 being in tune and any deviations higher or lower being higher or lower in tune respectively.
I wrote a script to load all of the presets into a single CSV, each row being a preset and each column being a value. After throwing out NaNs, I was left with about 12k presets. Not a bad amount of data if I say so myself.
After some exploratory data analysis, I noticed the following things:
Aside from the top 3 lines, order doesn’t matter for any of the other key-value pairs All the values were integers Some parameters were categorical. For example, with the parameter for “wave shape”, a sine wave would take the value 1, a saw wave would be 2, square 3, etc… Otherwise, most vars were between 0-127
Version Control
Just as a sanity check, I decided to see if I could convert a row in the CSV back into the preset form and write it to a text file. This would show that if the model just generates a row in the table, I can convert it into preset form easily.
All seemed good, but then I noticed something strange. The raw file from training and the second one is what I wrote to a file after loading it into the CSV and back sounded different. The text is (almost) the same so they should sound exactly the same.
But they didn’t.
After some more digging in the manual, I discovered something that complicated things immensely. I was saving all of my presets in the most recent Synth1 version number (1.13), even if my training data was from old Synth1 versions.
When Synth1 updates, sometimes changes are made to how the parameters behave. For example, between versions 1.06 and 1.07, negative values for filter amount were added. So now instead of the values 0-127 representing a filter range from 0-100%, they now represent a range from -100-100%.
To avoid messing up old patches, it looks like Synth1 simulates older versions of itself by looking at the version on the third line of the preset file, and then playing that preset with that specific version engine.
From a user standpoint, this makes a lot of sense because you don’t want every update to break all your patches. But from my super specific standpoint, this was a pain. I was writing everything to the latest version of Synth1 (1.12) because I thought it would remain the same. Guess not.
This throws a wrench in how I want to do everything. Now my one big 25,000 dataset is 8 small datasets. Below I listed how many preset files I had for each version.
| Version Num. | Count |
|---|---|
| 105 | 1200 |
| 106 | 4666 |
| 107 | 566 |
| 108 | 2594 |
| 109 | 4 |
| 111 | 121 |
| 112 | 2331 |
| 113 | 170 |
1) Do I try and write a script that “updates” older versions into newer ones to exactly match the sound? That’s tedious and probably not worth the effort.
2) Do I make the version a parameter that the ML model learns? I don’t think I know enough about ML to make that happen, plus that seems overly complicated.
3) Do I train on just a specific version? Better, but the largest dataset contains only around 4.5k data points compared to the original. That’s not even half.
4) Or, do I just throw all of it into the model and see what it spits out?
I decided to go with option three during my initial prototyping phase when building the model: using only version 1.06. It’s not a lot of data which will probably bite me later, but I’m impatient, too lazy to clean data, and want to start generating presets now dangit!
The Model: Part 1
Now I had to decide on what type of model I was going to use to generate the presets. The DX7 generator uses something called a Variational Autoencoder (VAE), which essentially learns to “compress” the data from a higher dimensional space into a lower one, and then tries to reconstruct it on the other side - allowing you to then tweak the values in the lower dimension to create novel samples in the higher dimension.
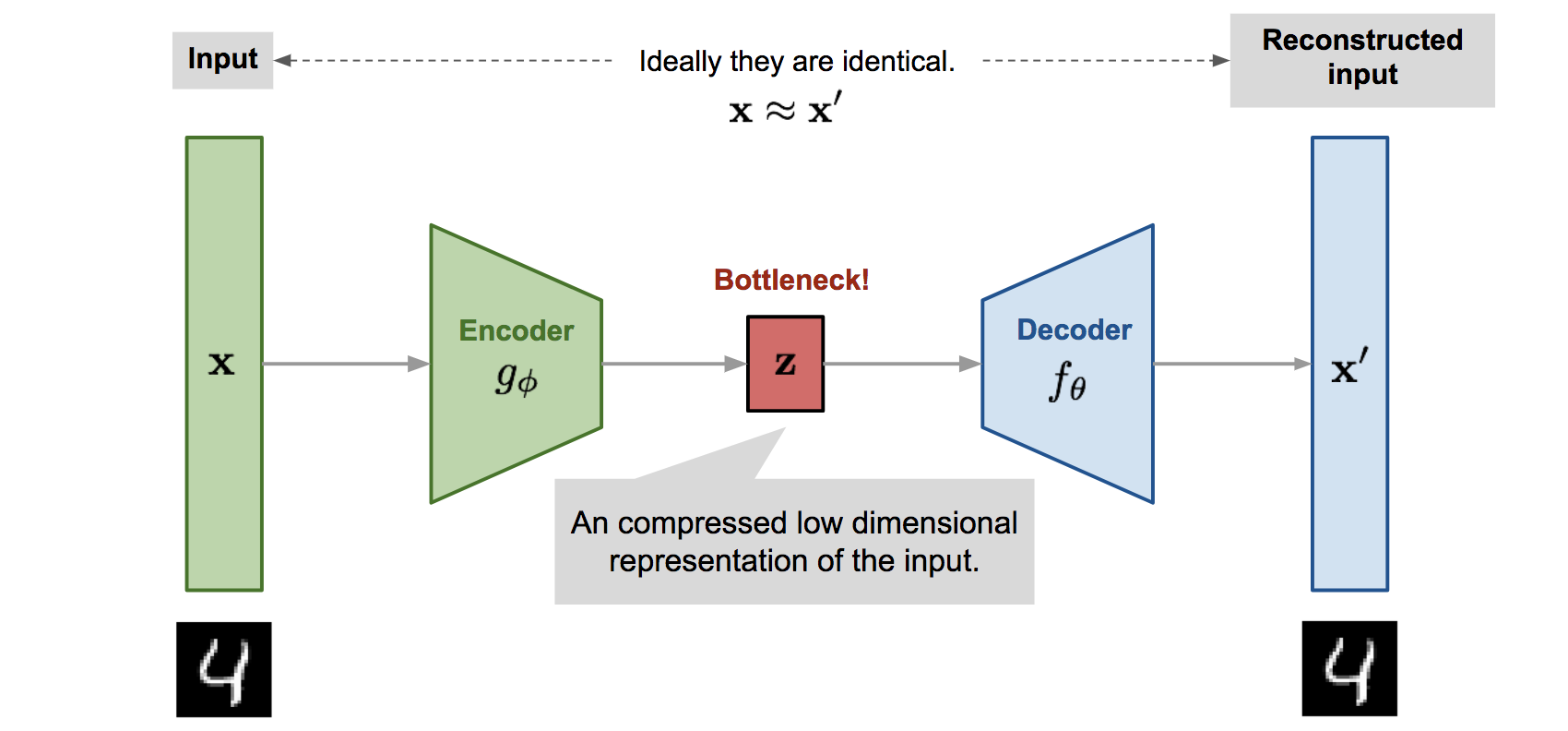
Fig 2. The structure of a VAE
However, I quickly realized that I don’t completely understand how VAEs work, so I decided to switch to something I understand better: Generative Adversarial Networks (GANs). Here’s a link to a good explanation, but here’s my TL;DR.
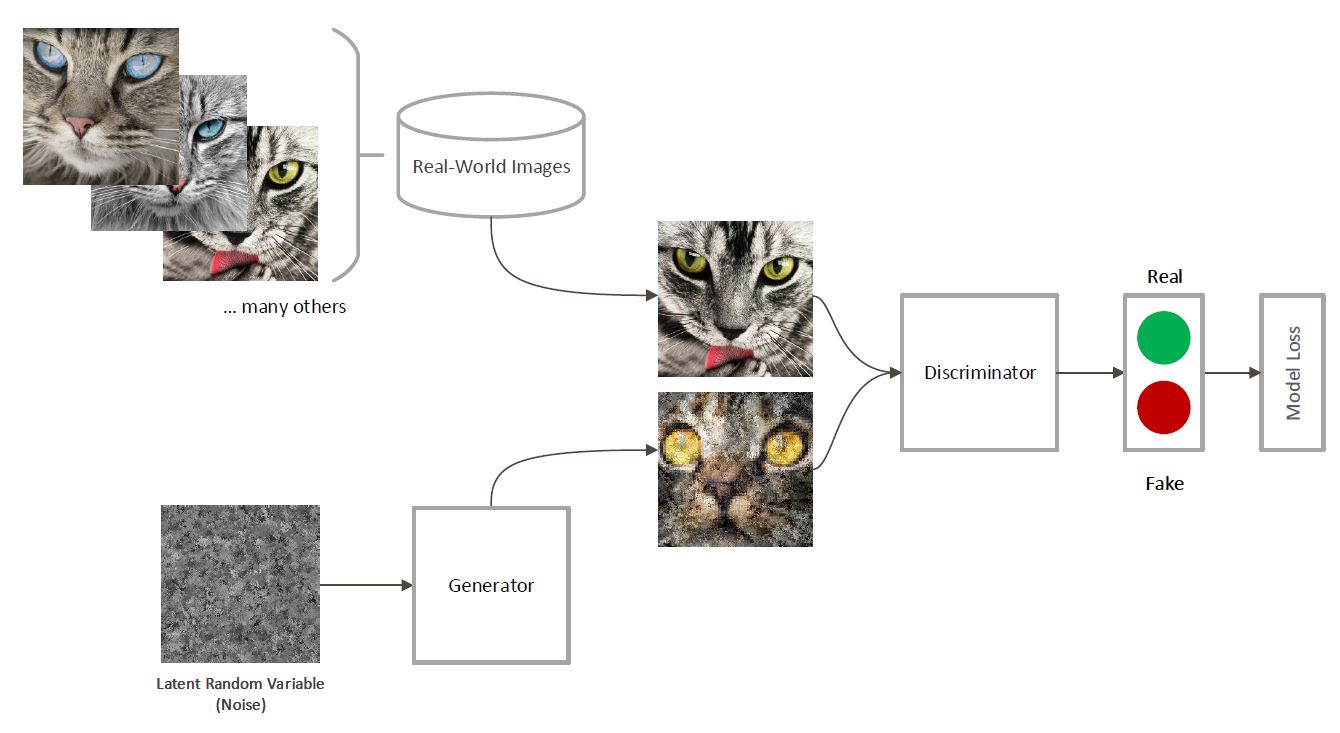
Fig 3. The structure of a GAN
A GAN is essentially making two neural networks fight against each other for our own benefit.
The AI is made up of two parts, a generator and a discriminator. The discriminator learns to detect whether a given preset is fake or not, while the generator learns how to fool the discriminator. Over time, the discriminator gets better at detecting fakes, while the generator gets better at generating fakes. At the end, the generator ends up producing pretty convincing fakes, which are then sent to you!
At least, that’s the theory.
So, I hunted around for some preexisting GAN code that I could use and I stumbled upon this repository, which hosted more GANs then I knew what to do with. Apparently, there’s lots of different tweaks and tricks that researchers have done over the years to improve performance. For my first batch, I just decided to go with the bare minimum GAN with no fancy addons.
Initial Results
Initial results were… interesting to say the least. They were quite abstract, noisy, and not really musical at all.
While I do enjoy funky and out there sounds such as these, this really isn’t what I set out to do with this project. I wanted to create more safe and playable patches.
It was at this point that I hit a wall for a few days. This is the point where years of experience reigns supreme over me taking a single machine learning course in undergrad, browsing the theory on Wikipedia, and reading a few Medium posts. This is where the aggressive searching and trawling through forum posts began.
Here’s what I learned and the revisions I made to my pipeline.
Data Wrangling: Part 2
After some tests, instead of training on all of the parameters; I sat down and tried to figure out the essentials. Here’s a list of all the params I thought weren’t adding too much to the sound and threw out of the model with some comments.
I also did some more data viz in the feature engineering jupyter notebook and dropped vars which had a low amount of variance.
to_drop = [
"name",
"osc1 fm modulation", #Don’t want to mess with FM
"osc2 pitch", #Coarse pitch: with this left in you have osc2 playing a completely different note than osc1, and 9 times outta 12 this just sounds bad. So I think it was better to just make both oscillators play the same note
"osc2 kbd track", #Keyboard tracking is usually something dialed down and is performer specific
"osc key shift",
"arp. on/off", #I don’t want to mess with the built in arpeggiator, it doesn’t add to the “sound”
"arp type",
"arp range",
"arp beat",
"arp gate",
"equalizer tone", #While EQ is important, for now I just decided to leave it up to the performer
"equalizer freq.",
"equalizer level",
"equalizer Q",
"pitch bend range" #Don’t want any pitch bend controls
In the end, my model was training on a much smaller subset of parameters, only about a dozen.
Finally, I did away with all pretense of separating versions and ended up throwing all 25k presets into one big batch. I knew this might not be completely accurate and there would be subtle errors, but at this point I was pulling out all the stops and wanted to get something workable.
Normalize me Cap’n!
Probably the first thing I should have done, but it never occurred to me. ML models usually perform better if you normalize the data to a fixed range beforehand, since that allows the model to push gradients better without them vanishing or exploding.
My model was using a tanh activation function, so my research found that normalizing my data to [-1,1] would give the best results.
One Hotline Bling
However, not all of my data was numerical. In fact, a lot of my data was categorical: wave shape, filter type, delay type, etc.
One of the biggest things I learned in my research was that if I tried to feed categorical data into the model as it exists now, it wouldn’t give good results. If a sine wave is represented by a 1, and a square wave is represented by a 3, the square wave isn’t really “three times as large” as the sine wave.
I learned that the way you usually remedy this is by using a one-hot encoding of the categorical variables. Instead of having a single variable take on a range of N values, instead add N new parameters and have a binary number indicate which data parameter is present.
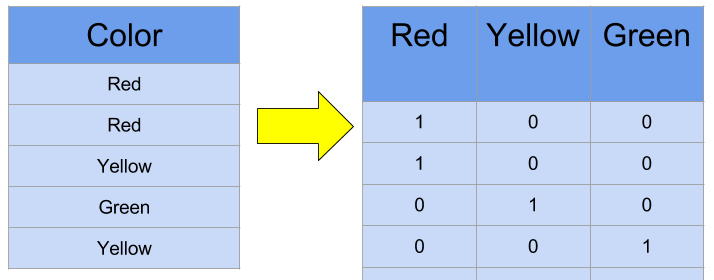
Fig 4. One-hot encodings example
So instead of having a single column “Wave Shape” contain [Sine, Saw, Square, Triangle], now we add four new columns to the table, and now a row having a Saw wave would have that represented as the bit vector [0,1,0,0].
In theory, this should work fine, but in practice there were some minor issues I had to overcome. When converting back from one-hot encoding to the standard categorical variable, my strategy was to round everything to the nearest integer since I already had that pipeline set up from the previous iteration.
For example, if the model spit out something such as [0.2,0.1,0.9,0.4] for the encodings, it would transform it into [0,0,1,0]. Then we can reverse the one hot encoding and get back our original categorical variable (Square). However, sometimes the model gave back some bogus answers such as [0.9,0.8,0.4,0.8], which would be [1,1,0,1].
In hindsight, I could have just fixed this by making the categorical variable the maximum value in the one hot encoding (which would be 0.9 in this case), but this problem didn’t occur that often so I was fine with just throwing out the bogus generated data.
The Model: Part 2
Now that my data was cleaned up, I looked into seeing if I could also tune up my model a bit more. I will be completely honest, I really don’t know the why and how these novel GAN variants end up being better then the stock GAN, so I’m not going to try and explain them. I’m just taking them as a black box that performs better than the standard GAN.
I ended up used a variant called the Wasserstein GAN GP. This is actually a variant of a variant, and based off of the Wasserstein GAN (or WGAN for short). The GP stands for “Gradient Penalty”
Again I’m not gonna say much about these two since I barely understand them myself, so here’s some resources to learn more about them :P
Training Takes Time
One thing I did take away with all of this is that I need to be more patient in training my models. In all previous iterations, I was only letting it train for a few thousand batches, which took around an hour or two.
However, after making the changes to my data above and changing my model code, I decided to just leave it on while I watched Avatar with my friends for a few hours. I came back, and a few more hours of training really did the trick! I was actually starting to get really cool results!
So, I decided to buckle down and leave the model to train overnight while I slept for around 8 hours. And that version is the model that is up online today.
Name Generation
You might notice that each synth preset also has a (somewhat) unique name. These are generated separately from the synth generation with a Recurrent Neural Network (RNN). RNNs are good at working with sequential data, like names.
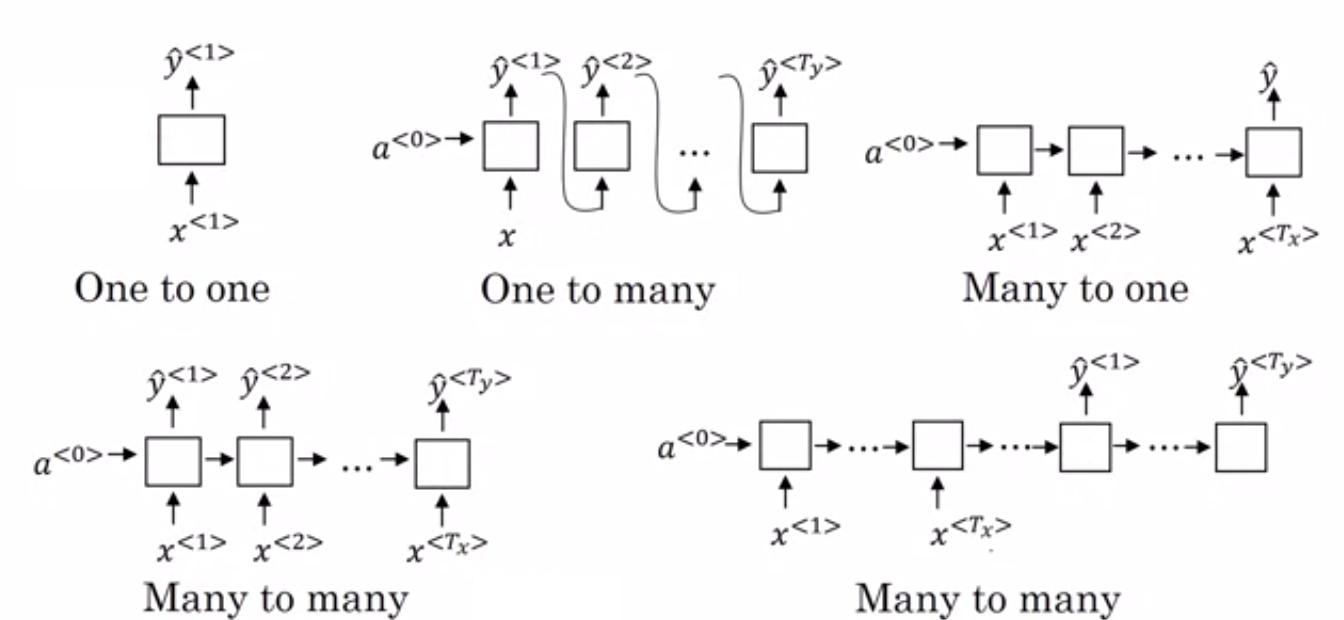
Fig 5. Various types of RRNs
My goal was to generate names based off of the parameters of the synth. This would be a “one to many” type problem in the image above: the input being the fixed length set of synth parameters and the output being the variable length name.
So for example, if the parameters of a synth made it sound like a bass patch, hopefully the name would contain the word “bass” in it somewhere.
I ended up doing something similar to when I refactored my GAN above; which is using more advanced models without trying super hard to understand the math. Instead of the standard RNN cell, I decided to use a LSTM based architecture, which is noted for being good at handling longer term dependencies.
Since this was less important (at least to me) than getting sounds playing, I didn’t spend as much time on the naming. Thus, in the actual production site, there’s quite a few duplicate names and some words show up more than others. (The name “SYNTH BASS” seems to show up a lot.)
Conclusion
Now that the model was finished, all that was left was to put it online and spread the word. I thought that would be easy, but it was much more of a hassle than I thought (which is probably a blog post for another day).